[Eng] Distributed Scheduler The Series: Episode 1 — The Naive Orchestrator
In Episode 0, we discussed why using just cron doesn’t work. We saw many problems with that approach—No retry logic, no logging, and as the system grows, we start seeing jobs silently fail and no way to tell why. So, like most engineers—I tried to solve the problem in the simplest way possible. Our first attempt was…
Add More Workers
If one worker isn’t enough, why don’t we just add more workers?
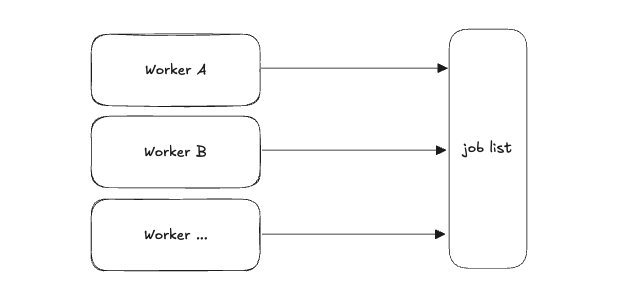
After adding them, we’ll see many problems instantly:
- Workers pull the same jobs, resulting in duplicated running—a.k.a race conditions
- Worse, some jobs don’t even run.
Why?
Every worker picks jobs from the same list, we don’t have something to track which jobs could run/skip/in-progress, and we don’t have a way to ensure that only one worker is executing a job at a time.
Okay then, let’s just…
Add a DB for Tracking State Changes + DB Lock
![]()
Perfect. Now, we could avoid all previous problems—one worker being a single-point of failure, jobs executing in duplicate, workers’ race conditions.
Here’s how it works: when a worker wants to fetch jobs, it acquires a lock. Other workers have to wait their turn. Sounds reasonable, right?
Good job until the database becomes our bottleneck because:
- Lock contention goes up—imagine 100 or more workers all fighting for the same lock.
- Query latency increases since the workers are trying to pull jobs and wait since it’s locked.
- Then, deadlocks happen. Worker A locks Job 1 and waits for Job 2, while Worker B locks Job 2 and waits for Job 1. They’re stuck waiting for each other forever.
So, we want something to manage jobs for our workers. Its responsibilities are:
- Fetch jobs from the database.
- Distribute jobs to workers.
Create a Naive Orchestrator
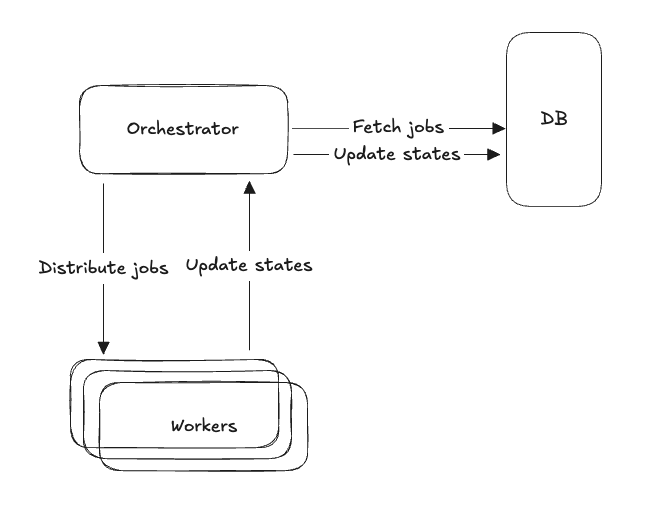
Yes, now we have a naive orchestrator to manage/orchestrate jobs for our workers.
The idea is simple: instead of all workers hitting the database directly, they ask the orchestrator for jobs. The orchestrator becomes the point that talks to the DB, pulls available jobs, and hands them out to workers. No more race conditions between workers!
Everything looks great, but again… we found problems, which are the same as our workers faced before—our orchestrator is a new single point of failure again. If the orchestrator dies, we all die! Jobs don’t even get fetched from the DB or distributed to the workers.
What if we scale more orchestrators?
It sounds good, right? Let’s scale the orchestrators…
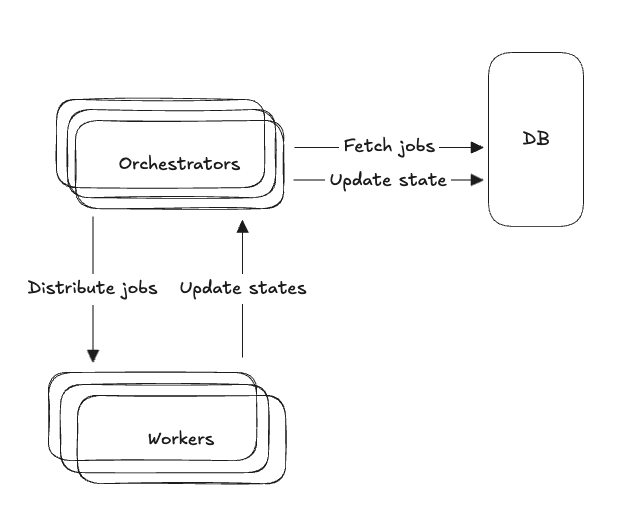
But here we go again, we face the same problems (again):
- Job duplication—now multiple orchestrators might fetch the same job.
- Race conditions—but this time it’s between orchestrators, not workers.
- And we know DB locking doesn’t work at scale.
We’ve basically moved the problem up one level. Instead of workers racing against each other, now orchestrators are racing against each other.
Isn’t the DB is the single-point of failure as well?
Yes, it is, but we can scale databases through clustering, sharding, replication, etc.—so, let’s focus on other things.
What’s the Right Way then?
We’ve hit a familiar wall—again:
- Adding more workers doesn’t work.
- Database locking can’t save us.
- And now, even our orchestration layer needs to scale reliably.
But how do we do that?
How do we coordinate job execution across multiple orchestrators without stepping on each other—or slowing down?
In the next episode, we’ll explore coordination strategies—let’s figure it out together! 🚀