[Eng] Distributed Scheduler The Series: Episode 2 — Only One Leader
In Episode 1, we tried to scale our orchestrator to remove the single point of failure, but we ended up creating the same problems:
- If we have multiple orchestrators running at the same time, they all try to fetch and schedule the same jobs.
- We get race conditions.
- We get duplicated job executions.
So, how do we have multiple instances running for safety (High Availability)? The solution is simple: “Leader Election”.
Leader Election
The leader election is, like its name, we elect one leader, and it’s the only one who does jobs.
Let’s say we have 3 orchestrators, we need to elect only 1 to be a leader, by following simple steps:
- ONLY ONE instance is elected as the Leader. Its job is to fetch tasks/jobs from the DB and dispatch them to workers.
- The other orchestrators who don’t get elected become Followers (or a.k.a. Standbys). Their only job is to watch the Leader.
- If the Leader dies, a follower steps up, wins the election, and resumes work immediately.
This solves our concurrency issues, because only one node schedules while solving our availability issue because if one node (leader) dies, another follower takes over.
Leader Election Mechanisms
It has many mechanisms for leader election, but I’ll list only 3-4 mechanisms and explore them one-by-one, and I will choose only one to implement as an example.
The Database Lease (a.k.a. The Lease Algorithm)
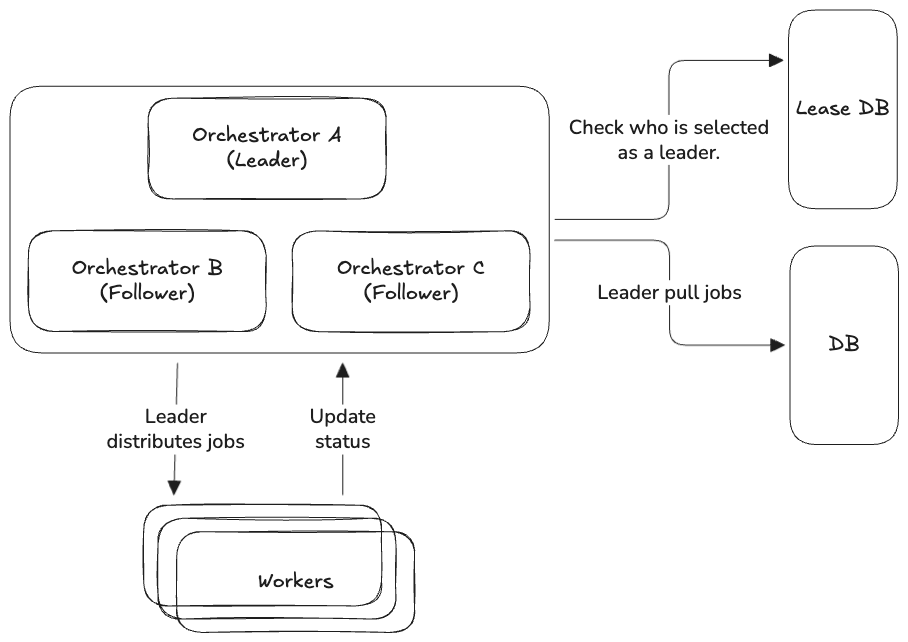 We run multiple orchestrators, but we force them to:
We run multiple orchestrators, but we force them to:
- Have ONLY ONE orchestrator to be selected as the leader.
- The others become followers (or standbys).
- If the leader dies, a follower steps up, wins the election and resumes work immediately.
Pros:
- Can use the shared resources which we already have, e.g., DB.
- Simplicity since it’s just an
INSERTorUPDATEquery. - Consistent since if the shared resources (e.g., DB) say who is the leader, it’s guaranteed to be a leader.
Cons:
- We will get frequent polling which adds load to the DB.
- Failover isn’t instant; it will take at least {lock_duration} + {poll_interval} to detect that we need a new election.
- Single Point of Failure (SPoF): If the DB goes down, election stops and yes, your applications which rely on the scheduler won’t work as well.
Token Ring
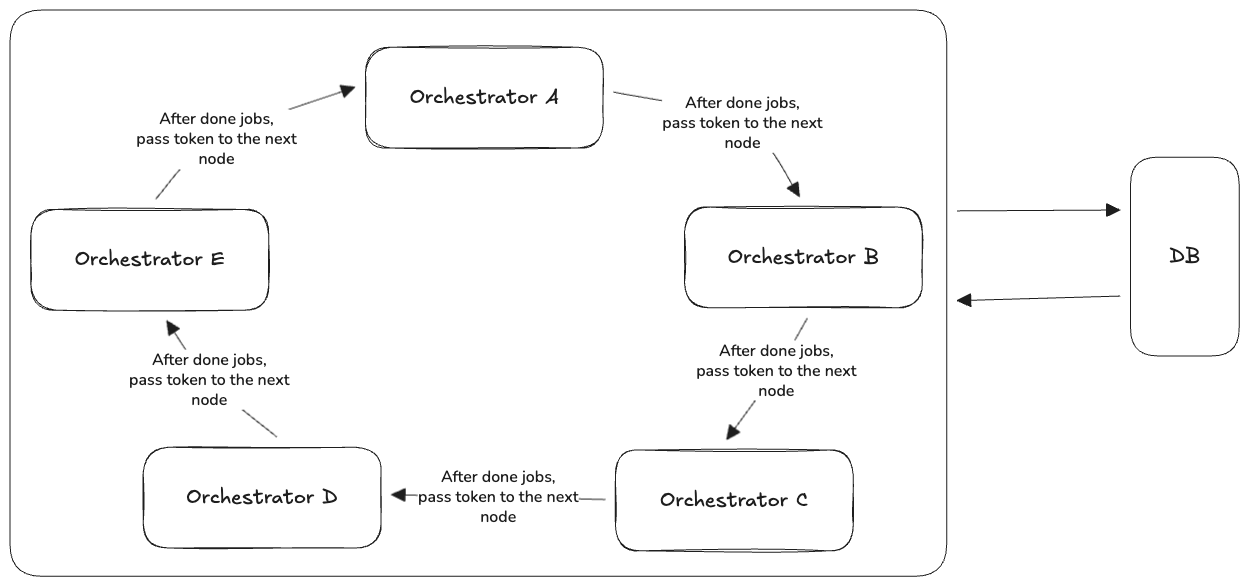 This is less about the electing, but it’s more about controlling access to shared resources by passing a single message called a “token” among the participants (in our case, it’s our leader candidates) in a ring structure. The only one who holds the token is allowed to do its jobs.
This is less about the electing, but it’s more about controlling access to shared resources by passing a single message called a “token” among the participants (in our case, it’s our leader candidates) in a ring structure. The only one who holds the token is allowed to do its jobs.
Pros:
- Fair distribution. Every node gets an equal turn to be the leader and no DB or master node gets overwhelmed.
Cons:
- If a node crashes while holding the token, the token vanishes. We need complex logic to detect this and regenerate one new token.
- Adding or removing orchestrator nodes requires re-configuring the ring logic dynamically.
The Consensus Algorithms (Raft/Paxos)
Instead of relying on a DB, which is a single point of failure itself, the nodes communicate directly with each other to elect and agree on a leader.
It SOUNDS simple: nodes vote for each other. If it gets a majority, it becomes the leader. They use a process to ensure everyone agrees who the leader is.
Pros:
- Mathematically proven to handle network partitions (split-brain) correctly.
- The nodes are the infrastructure, so no external dependencies needed.
Cons:
- Implementing Raft from scratch is difficult and error-prone.
- You need at least 3 nodes to become a high availability.
You could use etcd, ZooKeeper, or Consul, which background uses Raft instead of implementing them by yourself. Or if you want to build for learning purpose, you can follow more about the consensus algorithm here:
- Only 18 pages of Raft Paper.
- Implementing the Raft distributed consensus protocol in Go.
- Example Go Implementation under 500 lines.
Use Dependencies (K8s, Redis, etc.)
We have many tools to do this thing, e.g. K8s Leases, Redis with Redlock and SETNX.
Pros:
- Redis is much faster than SQL for locking.
- K8s is battle-tested for exactly this purpose.
- Libraries handle the logic for you.
Cons:
- We have to manage more dependencies.
- Using K8s lease might make it harder to run our applications locally.
- If Redis crashes, two nodes might think they are the leader simultaneously.
Which one we choose?
We will choose lease algorithm, because we want to follow KISS (Keep It Simple, Stupid) principle, so we assume that we will have DB for sure and we didn’t want other hard dependencies to manage (but yes, we need to manage DB to handle more loads instead). 🤪
The Simple Database Lease Implementation
It’s so simple like we mentioned above:
- Each candidate checks if it’s selected as a leader.
- If:
- Yes: Then do the jobs.
- No: Wait for an election.
type LeaseManager struct {
ID string
db *sql.DB
}
func (lm *LeaseManager) AcquireOrRenew(ctx context.Context) (bool, time.Time, error) {
query := `
INSERT INTO leases (resource_id, holder_id, expires_at)
VALUES ('news-fetcher-scheduler', $1, NOW() + INTERVAL '5 seconds')
ON CONFLICT (resource_id) DO UPDATE
SET holder_id = $1, expires_at = NOW() + INTERVAL '5 seconds'
WHERE holder_id = $1 OR leases.expires_at < NOW()
RETURNING expires_at;
`
var expiryTime time.Time
err := lm.db.QueryRowContext(ctx, query, lm.ID).Scan(&expiryTime)
if err != nil {
return false, time.Time{}, fmt.Errorf("lease manager: failed to acquire or renew lease: %w", err)
}
return true, expiryTime, nil
}And we could loop inside go-routine to acquire or renew the the lease.
type LeaderState struct {
mu sync.RWMutex
isLeader bool
leaseExpiry time.Time
}
func (s *LeaderState) Set(leader bool, expiry time.Time) {
s.mu.Lock()
defer s.mu.Unlock()
s.isLeader = leader
s.leaseExpiry = expiry
}
func (s *LeaderState) IsLeader() bool {
s.mu.RLock()
defer s.mu.RUnlock()
// We are only leader if the flag is true AND the lease hasn't expired yet
return s.isLeader && time.Now().Before(s.leaseExpiry)
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
state := &LeaderState{}
go func() {
for {
// The time returned is when the DB says this lease expires.
isLeader, expiryTime, err := leaseManager.AcquireOrRenew(ctx)
if err != nil {
log.Printf("Lease error: %v", err)
state.Set(false, time.Time{})
} else {
state.Set(isLeader, expiryTime)
}
// Sleep less than the lease duration (e.g., Lease is 10s, we sleep 3s)
time.Sleep(3 * time.Second)
}
}()
ticker := time.NewTicker(1 * time.Second)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case <-ticker.C:
if state.IsLeader() {
fmt.Println("I am the Leader. Doing work...")
// FetchJobs()
// DistributeJobs()
} else {
fmt.Println("I am a Follower. Standing by...")
}
}
}
}We are back to the same problems
We built the leader election with a high availability, so we can survive orchestrator failures.
But, we’re going back to having only one active node doing a ton of work.
- The leader fetches all jobs.
- The leader dispatches all jobs.
Let’s assume if we have 1M jobs. Our single leader has to fetch 1M rows and distribute them to workers one-by-one. It might drain the memory or we might take a lot of time to process them all. The followers are sitting there, eating popcorn, watching the leader do its thing, doing nothing until the leader dies.
We solved Availability, but we haven’t solved Scalability
How do we let multiple orchestrators work at the same time, without facing the same problems?
In the next episode, we will explore a more scalable way together! 🚀